Databases on Kubernetes. Database DevOps
- Introduction
- How to choose the right database for your service
- Database Load Balancer
- SQL
- Stored Procedures
- Performance
- Stateful and Stateless Applications
- Serverless Databases
- DataOps
- Database Continuous Integration
- Databases on Kubernetes
- Database DevOps
- Database Mesh
- KubeDB Cloud Native Postgress Database
- Cockroach Cloud Native Database
- Operator Lifecycle Manager (OLM)
- Spilo PostgreSQL Operator
- Zalando PostgreSQL Operator
- Crunchy Data PostgreSQL Operator
- Oracle 12c on OpenShift Container Platform
- Oracle Database Operator for Kubernetes
- SQL Server
- MySQL
- MariaDB
- PostgreSQL
- Percona MySQL
- Percona PostgreSQL Operator
- Redis
- Rockset
- PysonDB
- Clickhouse
- Apache Ignite
- Apache Druid
- Tools
- Time-Series Database
- Data Analytics and Visualization Tools
- Data Lakes
- Graph Databases
- Videos
- Tweets
Introduction
- thenewstack.io: How Database Load Balancing Completes the 3-Tiered Architecture 🌟
- sqlshack.com: SQL Database on Kubernetes: Considerations and Best Practices 🌟
- thenewstack.io: Just How Challenging Is State in Kubernetes? 🌟
- theregister.com: 75% of databases to be cloud-hosted by 2022, says Gartner while dishing on the weak points of each provider
- thenewstack.io: What Is Data Management in the Kubernetes Age?
- thenewstack.io: A Case for Databases on Kubernetes from a Former Skeptic
- hackernoon.com: Database Vs Data Warehouse Vs Data Lake: A Simple Explanation
- percona.com: DBaaS on Kubernetes: Under the Hood 🌟
- blog.crunchydata.com: Using Kubernetes? Chances Are You Need a Database 🌟
- thenewstack.io: Databases — Finally — Get Containerized
- percona.com: Autoscaling Databases in Kubernetes for MongoDB, MySQL, and PostgreSQL
- levelup.gitconnected.com: How to design a system to scale to your first 100 million users Think Big, Do Small, Learn Fast
- magalix.com: Kubernetes And Databases 🌟
- towardsdatascience.com: SQL vs. NoSQL: How to Select from 12 Database Types 🌟🌟 When to use SQL vs. NoSQL database? Deep dive, differences, decision tree, and cloud cheatsheet to choose the best database for your data type and use case.
- andrewlock.net: Running database migrations when deploying to Kubernetes 🌟 Deploying ASP.NET Core applications to Kubernetes - Part 7. Learn how to run database migrations with init containers and Jobs in Kubernetes.
- redislabs.com: What is a “Databaseless” (DBLess) Architecture, and Why It’s the Future 🌟 DBLess architecture provides a new approach to data pipeline and backend architecture. Just like the terms serverless, stateless, and NoSQL, it attempts to provide more options for architects to think about.
- red-gate.com: Designing Highly Scalable Database Architectures
- dev.to: Introduction Migrations
- medium: Not using trendy technologies is the best thing for your Startup! I refused to use MongoDB and I convinced my company to use a SQL relational database system.
- thenewstack.io: Database-as-a-Service: A Key Technology for Agile Growth
- cloud.redhat.com: OpenShift Commons Briefing: Database Disaster Recovery Made Easy with Annette Clewett (Red Hat) and Andrew L’Ecuyer (Crunchy Data)
- thenewstack.io: A Case for Databases on Kubernetes from a Former Skeptic
- hackernoon.com: Practical Transaction Handling in Microservice Architecture
- thenewstack.io: Data on Kubernetes: Operators, Tools Need Standardization
- medium: How to Put a Database in Kubernetes For example, a deployment of Apache Cassandra will typically use a StatefulSet to launch pods across available Kubernetes worker nodes, with each Cassandra pod having its own PersistentVolumeClaim that can be preserved and reused if the pod needs to be replaced.
- thenewstack.io: Kubernetes Will Revolutionize Enterprise Database Management
- dok.community: Data on Kubernetes 2021 Report Standardization, consistency and the ability for developers to self-manage - are among the top 3 important factors in the organization’s decision to run stateful workloads on Kubernetes.
- cloud.redhat.com: Simplifying Database Cloud Service Access
- venturebeat.com: The rise of Kubernetes and its impact on enterprise databases
- vladmihalcea.com: Single-Primary Database Replication
- treblle.com: How does Treblle scale on AWS without breaking the bank? A completely scalable intake solution that didn’t require a database because all the data was stored on S3.
- intellipaat.com: Difference between DBMS and RDBMS DBMS and RDBMS sound very similar, but can be confusing to those who are completely new to the database domain. Both of them are based on the technology of storing data. However, we will dive into this DBMS vs RDBMS blog to learn the difference between them.
- betterprogramming.pub: Multi-Tenancy Support With Spring Boot, Liquibase, and PostgreSQL A step-by-step guide on how to implement multi-tenancy.
- thenewstack.io: How Kubernetes and Database Operators Drive the Data Revolution
- thenewstack.io: How Radical API Design Changed the Way We Access Databases
- architecturenotes.co: Things You Should Know About Databases This is the first post in a series called Things You Should Know. Think of it as a primer to level set from base principles on various topics. Today we are discussing databases!
- vladmihalcea.com: A beginner’s guide to database multitenancy
- itnext.io: How to Run Databases in Kubernetes 90% of the customers believe it is ready for stateful workloads, and a large majority (70%) are running them in production with databases topping the list. Companies report significant benefits to standardization, consistency, and management as key drivers.
- thenewstack.io: More Database, Analytics Workloads Ran on Kubernetes in 2022 More than three in four participants in the new Data on Kubernetes survey now acknowledge the use of databases on Kubernetes, up from 50% in 2021.
- medium.com/@bijit211987: Kubernetes ready for stateful workloads and to Revolutionize Enterprise Database Management
- medium.com/javarevisited: Top Performance issues every developer/architect must know — part 1-Database
- infoq.com: Create Your Distributed Database on Kubernetes with Existing Monolithic Databases
- dineshchandgr.medium.com: Why do we need a Database Connection Pool? -every programmer must know In this article, we looked at what is Database connection and its life cycle. Then we saw the drawbacks of creating connections on the fly and then saw the need to use a Database Connection Pool. We also looked at the design patterns on where to place the connection pool. We have then looked at the performance issues that can arise from the Database connection pool and concluded the article by looking at the common connection pool frameworks used in Java.
- medium.com/fintechexplained: What Is Database Sharding? Learn How Splitting Database Across Multiple Machines Improves Performance By Processing Requests In Parallel For High Volume Applications
- blog.equationlabs.io: Managing database migrations safely in high replicated k8s deployment 🌟 In this article, you will learn how to run database migrations in Kubernetes using the Job resource, init containers and rolling updates.
- blog.equationlabs.io: Managing database migrations safely in high replicated k8s deployment In this article, you will learn how to run database migrations in Kubernetes using the Job resource, init containers and rolling updates
- thenewstack.io: Distributed Database Architecture: What Is It?
- medium.com/@mkremer_75412: Why Postgres RDS didn’t work for us (and why it won’t work for you if you’re implementing a big data solution)
How to choose the right database for your service
Database Load Balancer
SQL
- digitalocean.com: How To Use WHERE Clauses in SQL
- intellipaat.com: SQL vs MySQL - Key Differences Between SQL and MySQL
- vettabase.com: How slow is SELECT * ?
- towardsdatascience.com: How to Use SQL Cross Joins The SQL join you never knew existed
- vladmihalcea.com: SQL EXISTS and NOT EXISTS
- vladmihalcea.com: Default Database Primary, Foreign, and Unique Key Indexing
- blog.jooq.org JAVA, SQL AND JOOQ. Best Practices and Lessons Learned from Writing Awesome Java and SQL Code. Get some hands-on insight on what’s behind developing jOOQ.
- vladmihalcea.com: SQL LEFT JOIN – A Beginner’s Guide
- vladmihalcea.com: SQL JOIN USING – A Beginner’s Guide
- gcreddy.com: SQL Step by Step Videos
- freecodecamp.org: SQL Joins Tutorial: Cross Join, Full Outer Join, Inner Join, Left Join, and Right Join
- freecodecamp.org: SQL Join Types – Inner Join VS Outer Join Example
- freecodecamp.org: The SQL Inner Join Command: Example Syntax
- freecodecamp.org: SQL Inner Join – How to Join 3 Tables in SQL and MySQL
- geeksforgeeks.org: Best Practices for SQL Query Optimization
- towardsdatascience.com: You Should Use This to Visualize SQL Joins Instead of Venn Diagrams
- vladmihalcea.com: MySQL JSON_TABLE – Map a JSON object to a relational database table
Alternatives to SQL
- infoworld.com: Beyond SQL: 8 new languages for data querying SQL has dominated data querying for decades. Newer query languages offer more elegance, simplicity, and flexibility for modern use cases.
Stored Procedures
- blog.yugabyte.com: Are Stored Procedures and Triggers Anti-Patterns in the Cloud Native World?
- stackoverflow.com: Is the usage of stored procedures a bad practice?
- softwareengineering.stackexchange.com: What is the best practice about microservice architecture for consuming many stored procedures in the same database?
Performance
- betterprogramming.pub: 8 Techniques To Speed up Your Database “If everything seems under control, you’re not going fast enough”
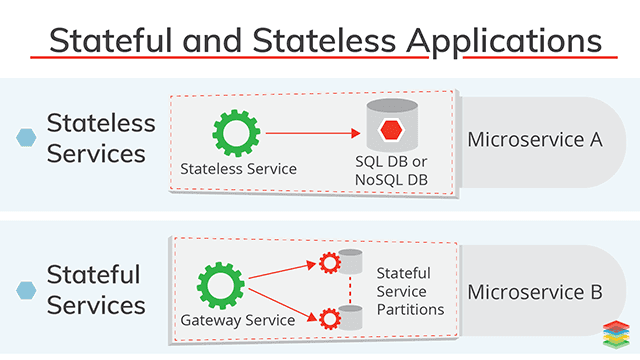
Stateful and Stateless Applications
- xenonstack.com: Stateful and Stateless Applications Best Practices and Advantages
- threadreaderapp.com: Kelsey Hightower: “Kubernetes has made huge improvements in the ability to run stateful workloads including databases and message queues, but I still prefer not to run them on Kubernetes” 🌟
- thenewstack.io: Data on Kubernetes: The Next Frontier “The interesting opportunity I see in the Kubernetes ecosystem,” Evenson continued, “is that, with the advent of custom resources and Kubernetes, you can build bespoke APIs for your application really easily. We’re in the world of operator explosion. In essence, it makes Kubernetes applications aware.”
- dzone: Kubernetes and Running Stateful Workloads 🌟
- towardsdatascience.com: Understanding the Relational Model of Database Management Systems 🌟
- openshift.com: OpenShift, Databases and You: When to Put Containerized Database Workloads on OpenShift 🌟
- sixfold.medium.com: Reducing database queries to a minimum with DataLoaders
- stackexchange.com/performance 🌟
Serverless Databases
DataOps
- dzone: 2021: The Year of DataOps Centralizing an organization’s data in a cloud data warehouse gives all stakeholders big-picture access to everything going on at the company.
- thenewstack.io: The Benefits and Drawbacks of DataOps in Practice
Database Continuous Integration
Databases on Kubernetes
- cloud.google.com: To run or not to run a database on Kubernetes - What to consider
- reddit.com: What’s the best, proper way of running a database cluster on top of Kubernetes?
- caylent.com: The Pros and Cons of Running Production Databases as Containers
- learnk8s.io: Provisioning cloud resources (AWS, GCP, Azure) in Kubernetes
- cloudsavvyit.com: Should You Run a Database in Docker?
Database DevOps
- informationweek.com: Can Enterprises Benefit From Adopting Database DevOps?
- medium: DevOps and Databases — The forgotten automation
Database Mesh
- medium.com/@database-mesh: Database Mesh 2.0: Database Governance in a Cloud Native Environment This article reviews the background of Database Mesh, reexamines the value of Database Mesh 1.0, and introduces the new concepts, ideas, and features of Database Mesh 2.0. It also attempts to explore the future of Database Mesh
KubeDB Cloud Native Postgress Database
- kubedb.com Run production-grade databases easily on Kubernetes
Cockroach Cloud Native Database
- Wikipedia: CockroachDB is a project that is designed to store copies of data in multiple locations in order to deliver speedy access. It is described as a scalable, consistently-replicated, transactional datastore.
- Cockroach
- cockroachlabs.com: Automated database operations with Terraform
- blog.cloudneutral.se: Running CockroachDB TPC-C benchmark on GKE This article demonstrates how to run a TPC-C 2.5K benchmark on a self-hosted, 3-node, single-region CockroachDB cluster on Google Kubernetes Engine (GKE)
Operator Lifecycle Manager (OLM)
Spilo PostgreSQL Operator
- Spilo: HA PostgreSQL Clusters with Docker Spilo is a Docker image that provides PostgreSQL and Patroni bundled together. Patroni is a template for PostgreSQL HA.
- Patroni
- How I’ve Set Up HA PostgreSQL on Kubernetes (powered by Patroni, a template for PostgreSQL HA)
Zalando PostgreSQL Operator
- Zalando Postgres Operator Postgres operator creates and manages PostgreSQL clusters running in Kubernetes
- vitobotta.com: Postgres on Kubernetes with the Zalando operator
Crunchy Data PostgreSQL Operator
Oracle 12c on OpenShift Container Platform
- medium: Running Oracle 12c on OpenShift Container Platform Oracle is now offering an Oracle 12c image on Docker Hub for dev/test purposes (license still required for Prod).
- dockerhub: Oracle Database 12c Enterprise Edition
Oracle Database Operator for Kubernetes
- https://github.com/oracle/oracle-database-operator
- pasimoes.dev: Let the Oracle Database Operator for Kubernetes Do the Job
SQL Server
- Expanding SQL Server Big Data Clusters capabilities, now on Red Hat OpenShift
- devblogs.microsoft.com: DevOps for Azure SQL 🌟
- khalidabuhakmeh.com: Running SQL Server Queries In Docker
MySQL
- twindb.com: Verify MySQL Backups With TwinDB Backup Tool
- blog.eduguru.in: mysql create index on table
- percona.com: MySQL 101: Parameters to Tune for MySQL Performance
- pub.towardsai.net: Step-by-Step Design of Enhanced Entity-Relationship (EER) in MySQL Database schema relationships of tables
- dbasecenter.com: The top 5 MySQL performance variables
- opensource.com Tune your MySQL queries like a pro. Optimizing your queries isn’t a dark art; it’s just simple engineering.
- percona.com: MySQL on Kubernetes with GitOps 🌟
- Moco MOCO is a Kubernetes operator for MySQL created and maintained by Cybozu.
- cloudsavvyit.com: How to Run PHPMyAdmin in a Docker Container
- percona.com: Storing JSON in Your Databases: Tips and Tricks For MySQL Part One
- tusacentral.com: MySQL on Kubernetes demystified
- dzone: PostgreSQL vs MySQL Performance
- thenewstack.io: Deploy MySQL and phpMyAdmin with Docker
MariaDB
PostgreSQL
- momjian.us: Mastering PostgreSQL Administration [pdf]
- 9 High-Performance Tips when using PostgreSQL with JPA and Hibernate
- dzone: A Guide to SQL Triggers: Setting up Database Tracking in PostgreSQL SQL triggers are less common but can be a great solution for certain situations. I’ll show how to use triggers in Postgres to enforce data integrity and track changes to a database.
- migops.com: pgBackRest – The Best Postgres Backup Tool with a very active community
- towardsdatascience.com: Practical Introduction to PostgreSQL
- percona.com: An Overview of Sharding in PostgreSQL and How it Relates to MongoDB’s
- blog.crunchydata.com: How to Setup PostgreSQL Monitoring in Kubernetes
- blog.flant.com: Comparing Kubernetes operators for PostgreSQL
- blog.crunchydata.com: Cut Out the Middle Tier: Generating JSON Directly from Postgres
- percona.com: How to Adjust Linux Out-Of-Memory Killer Settings for PostgreSQL
- Postgres.app The easiest way to get started with PostgreSQL on the Mac
- devopscube.com: How to Deploy PostgreSQL Statefulset in Kubernetes With High Availability
- blog.crunchydata.com: Quickly Document Your Postgres Database Using psql Meta-Commands
- Why Postgres?
- Its fully open source, so control over destiny
- Features are comparable to Oracle, so minimizes mental friction of the move
- blog.crunchydata.com: Devious SQL: Message Queuing Using Native PostgreSQL
- percona.com: Should I Create an Index on Foreign Keys in PostgreSQL?
- percona.com: PostgreSQL 14 Database Monitoring and Logging Enhancements
- theregister.com: MySQL a ‘pretty poor database’ says departing Oracle engineer PostgreSQL a better option for open source RDBMS, he claims
- wanago.io: Creating views with PostgreSQL
- percona/pg_stat_monitor PostgreSQL Statistics Collector
- blog.crunchydata.com: A Postgres Primer for Oracle DBAs
- blog.crunchydata.com: Postgres Indexes for Newbies
- dev.to: REST Data Service on YugabyteDB / PostgreSQL
- orgrim/pg_back: Simple backup tool for PostgreSQL pg_back dumps databases from PostgreSQL
- sqlrevisited.blogspot.com: MySQL vs PostgreSQL? Pros and Cons
- adamtheautomator.com: How to Deploy Postgres to Kubernetes 🌟 In this step-by-step tutorial, you will learn how to securely deploy Postgres to Kubernetes using two methods:
- Helm charts
- YAML configurations
- purnapoudel.blogspot.com: How to Configure PostgreSQL with SSL/TLS support on Kubernetes This tutorial describes detailed steps to deploy PostgreSQL on Kubernetes with SSL/TLS support using PersistentVolume, configMap, and secrets along with possible issues, troubleshooting steps and work-around.
Percona MySQL
- Percona.com: Percona Kubernetes Operator for Percona XtraDB Cluster
- medium: Upgrading MySQL (Percona Server) from 5.7 to 8.0
- percona.com: MySQL 101: How to Find and Tune a Slow SQL Query
- percona.com: Storing Kubernetes Operator for Percona Server for MongoDB Secrets in Github
- percona.com: Migration of a MySQL Database to a Kubernetes Cluster Using Asynchronous Replication
Percona PostgreSQL Operator
Redis
- RedisLabs/redis-enterprise-k8s-docs: Deploying Redis Enterprise on Kubernetes This page describes how to deploy Redis Enterprise on Kubernetes using the Redis Enterprise Operator.
- tech.trell.co: Redis Cluster Creation Automation
- containiq.com: Deploying Redis Cluster on Kubernetes | Tutorial and Examples
- blog.devgenius.io: How to use Redis Pub/Sub in your Python Application 🌟
Rockset
PysonDB
- https://pysondb.github.io/pysonDB/
- freecodecamp.org: How to Get Started with PysonDB PysonDB is yet another document-oriented database written in pure Python. Developed by Fredy Somy, it is simple, lightweight, and efficient.
Clickhouse
- clickhouse.com ClickHouse is a column-oriented database management system (DBMS) for online analytical processing of queries (OLAP).
- Altinity/clickhouse-operator The ClickHouse Operator creates, configures and manages ClickHouse clusters running on Kubernetes
- radondb/radondb-clickhouse-kubernetes Open Source,High Availability Cluster,based on ClickHouse
- tech.marksblogg.com: Monitor ClickHouse column oriented database with Prometheus & Grafana
Apache Ignite
- Apache Ignite Distributed Database For High-Performance Computing With In-Memory Speed
- dzone: Stateful Microservices With Apache Ignite This article explains how to implement stateful microservices architecture for Spring Boot applications with distributed database Apache Ignite.
Apache Druid
- Apache Druid Druid is a high performance, real-time analytics database that delivers sub-second queries on streaming and batch data at scale and under load.
- dev.to: Apache Druid: overview, running in Kubernetes and monitoring with Prometheus In this detailed tutorial, you will learn how to install, run and monitor Apache Druid on Kubernetes — a columnar database designed to work with large amounts of data
Tools
- SHMIG A database migration tool written in BASH consisting of just one file - shmig.
- DATA-DOG/go-sqlmock Sql mock driver for golang to test database interactions
- datafold/data-diff Efficiently diff rows across two different databases.
- medium.com/@nomulex: How to create an ssh tunnel to a remote database in Kubernetes 🌟
Time-Series Database
Data Analytics and Visualization Tools
- opensource.com: Make your data boss-friendly with EDA - Enterprise Data Analytics - EDA
- thenewstack.io: Kubernetes-Run Analytics at the Edge: Postgres, Kafka, Debezium
Data Lakes
- unifieddatascience.com: Data lake design patterns on Azure (Microsoft) cloud
- unifieddatascience.com: Data lake design patterns on AWS (Amazon) cloud
- unifieddatascience.com: Data lake design patterns on google (GCP) cloud
Graph Databases
- SQErzo: Tiny ORM for Graph databases Tiny ORM for graph databases: Neo4j, RedisGraph, AWS Neptune or Gremlin
- towardsdatascience.com: At Its Core: How Is a Graph Database Different from a Relational One? It’s easy to come up with some answers by simply Googling the topic, however, as I found, most answers list benefits mostly superficially
Videos
Click to expand!
Tweets
Click to expand!
Kubernetes has made huge improvements in the ability to run stateful workloads including databases and message queues, but I still prefer not to run them on Kubernetes.
— Kelsey Hightower (@kelseyhightower) February 13, 2018
Postgres is what happens when tech gets so good, for so long, it becomes boring. Dope since the 80s. https://t.co/zeoagBfMvW
— Kelsey Hightower (@kelseyhightower) December 28, 2020
Stack Overflow's SQL Server is at 4% CPU with 500M queries/day https://t.co/wX9Od749ik https://t.co/1BAuEV9VgT
— Lukas Eder (@lukaseder) August 18, 2021
PostgreSQL for relational.
— Jaana Dogan at KubeCon ヤナ ドガン (@rakyll) October 13, 2021
PromQL for monitoring.
Two big alignments across the industry.
I'm super curious, how many people have successfully migrated their databases from Oracle to Postgres in production? I'm talking 100% migration with Oracle being turned off at the end.
— Kelsey Hightower (@kelseyhightower) November 1, 2021
Kubernetes can only meet stateful services half way. We need direct changes in databases, message brokers, and other stateful systems if we want to see a future where Kubernetes becomes the preferred destination to run them. The @vectorizedio team is doing their part. https://t.co/w94Q56nnXM
— Kelsey Hightower (@kelseyhightower) November 8, 2021
Sometimes we work for a database and need to connect to another (#migration ;) so I explained to a colleague the difference between Oracle SERVICE_NAME and SID. Pasting it here in case it helps 🧵
— Franck Pachot 🚀 (@FranckPachot) February 2, 2022
Kubernetes Database Operator is useful for building scalable database servers as a database cluster. But migrating existing databases to k8s requires a lot of manual work due to having to create new artifacts.
— konveyor.io (@Konveyor_io) February 4, 2022
At our next meetup, we'll demo an open-source tool to solve this. pic.twitter.com/o55vnyITV2
Surprising number of devs today don't seem to know how to write their own database schemas. Is SQL really that out of fashion?
— Joyce Park (@troutgirl) April 2, 2022
It is often surprising how little is known about how databases operate at a surface level, considering they store almost all of the states in our applications. Things You Should Know About Databases. pic.twitter.com/SAX5wHaS3m
— Architecture Notes (@arcnotes) October 27, 2022
Partitioning is the process of storing a large database across multiple machines.
— Fernando 🇮🇹🇨🇭 (@Franc0Fernand0) December 17, 2022
Here are the popular partitioning architectures with their benefits and costs: {1/8} ↓ pic.twitter.com/85JdhcISJq
What is the 𝗦𝗤𝗟 𝗤𝘂𝗲𝗿𝘆 𝗼𝗿𝗱𝗲𝗿 𝗼𝗳 𝗘𝘅𝗲𝗰𝘂𝘁𝗶𝗼𝗻?
— Aurimas Griciūnas (@Aurimas_Gr) May 9, 2023
There are many steps involved in optimising your SQL Queries. It is helpful to understand the order of SQL Query Execution as we might have constructed a different picture mentally.
The actual order is as… pic.twitter.com/ApvRbkH652
State of Database 2023 https://t.co/uXd2sM7dq9 pic.twitter.com/sGBmXqT3CA
— Architecture Notes (@arcnotes) August 6, 2023